Qu'est-ce que Spark ? Le Layer 2 Bitcoin derrière la nouvelle vague de wallets self-custodial

La couche de base de Bitcoin est volontairement conservatrice. Ce n'est pas un bug. C'est ce qui rend le système vérifiable par des utilisateurs ordinaires, résistant aux changements arbitraires de règles et difficile à capturer. Mais cela signifie aussi que Bitcoin n'est pas conçu pour enregistrer directement on-chain chaque petit paiement dans le monde.
Un réseau monétaire mondial a besoin d'au moins 2 fonctions différentes. La 1re est le règlement final : la capacité de détenir et transférer de la valeur avec des garanties fortes, une vérification publique et aucun intermédiaire de confiance. La 2e concerne les paiements du quotidien : la capacité de déplacer de petits montants rapidement, à faible coût et avec une expérience que des utilisateurs normaux peuvent comprendre.
Lightning a été la première réponse sérieuse de Bitcoin à cette tension, il a rendu possibles les paiements instantanés en déplaçant l'activité dans des canaux de paiement, tout en conservant Bitcoin comme couche de règlement final. Mais Lightning n'est pas simple à intégrer dans un wallet mobile entièrement self-custodial. Les canaux, la liquidité entrante, le routage, les sauvegardes, les contraintes de disponibilité permanente et la gestion de liquidité restent difficiles à masquer sans introduire un fournisseur de service.
Les wallets custodial ont résolu le problème d'expérience utilisateur en supprimant le problème de la self-custody. Un utilisateur ouvre une application, voit un solde, reçoit des paiements et envoie instantanément. Mais le compromis est évident : l'intermédiaire détient les fonds. Cela crée une exposition réglementaire, un risque opérationnel, de possibles restrictions de retrait, un risque de censure et le problème familier que Bitcoin cherchait justement à éviter, les tiers de confiance.
🪙 Le Bitcoin (BTC) est-il vraiment une monnaie ?
Spark arrive dans ce paysage comme un compromis différent. Il cherche à offrir aux wallets et aux applications une expérience utilisateur proche d'un wallet Lightning custodial, tout en évitant la custody directe au sens classique. Les fonds sont censés être récupérables sur Bitcoin L1 et les paiements peuvent être rapides, peu coûteux et compatibles avec Lightning.
Mais Spark ne doit pas être compris comme une solution magique, il ne supprime pas totalement la confiance des paiements Bitcoin.
Spark se comprend mieux comme une réponse non seulement au problème de scalabilité de Bitcoin, mais aussi au coût réglementaire et opérationnel des wallets Bitcoin custodial. Sa promesse est attractive précisément parce qu'elle permet aux wallets de conserver une grande partie du confort de la custody, tout en renvoyant une partie de la charge de la garde vers les utilisateurs. Cela peut être utile, voire nécessaire pour certains produits, mais ce n'est pas la même garantie que de détenir directement un UTXO Bitcoin normal on-chain, ou que de disposer d'un canal Lightning ou d'un VTXO Ark.
Qu'est-ce que Spark ?
Spark est un Layer 2 Bitcoin conçu pour les paiements rapides, peu coûteux et les applications de wallet. Il repose sur des statechains, une famille de protocoles dans laquelle le droit de dépenser des fonds liés à Bitcoin peut être transféré off-chain sans déplacer les coins sous-jacents on-chain à chaque paiement.
En termes simples, Spark permet à un utilisateur de détenir un solde qui peut se déplacer rapidement à l'intérieur du système Spark, tout en restant connecté à Bitcoin via des transactions de sortie pré-signées et au Lightning Network via des swaps. L'utilisateur n'a pas besoin d'ouvrir un canal de liquidité, de gérer la liquidité entrante, de faire tourner un node ou de comprendre le routage. Les wallets et les fournisseurs de service peuvent abstraire la plus grande partie de cette complexité.
Spark n'est pas une blockchain séparée, ni un rollup, ni une plateforme de smart contracts. Sa propre documentation le décrit comme une solution de scaling off-chain construite sur des statechains, sans VM, sans séquenceur et sans couche de consensus externe. L'objectif est plus étroit : rendre les transferts de bitcoins et de tokens rapides et peu coûteux, tout en préservant l'interopérabilité avec Lightning et un chemin de sortie vers Bitcoin L1.
Le système repose sur plusieurs acteurs : une Spark Entity est le groupe d'opérateurs qui fait fonctionner un Spark, un Spark Operator est un participant individuel dans ce groupe, et un Spark Service Provider peut aider les utilisateurs à entrer et sortir de Spark, tout en fournissant éventuellement une connectivité Lightning.
Cela rend Spark différent à la fois d'un wallet custodial et d'un simple wallet Bitcoin. Dans un wallet custodial, le service détient les fonds. Dans un wallet Bitcoin normal, l'utilisateur contrôle directement des UTXO. Spark se situe entre ces 2 modèles : l'utilisateur dispose de matériel de clé et d'un chemin de sortie, mais les paiements ordinaires dépendent d'un ensemble d'opérateurs qui coordonne les signatures, met à jour l'état et reste disponible.
Cette zone grise est tout le sujet de Spark.

Pourquoi Spark existe : UX, custody et régulation
Bitcoin L1 est une couche de règlement, pas une base de données de paiements retail
La couche de base de Bitcoin est optimisée pour un règlement crédible, les blocs sont limités, les frais augmentent lorsque la demande de blockspace augmente, et la confirmation prend du temps. Ces contraintes sont la raison pour laquelle un full node peut vérifier l'ensemble du système et faire respecter les règles sans demander l'autorisation à une entreprise, à un exchange ou à un ensemble de validateurs.
Mais cette architecture ne permet pas de scaler les paiements retail du quotidien en mettant simplement chaque café, tip sur un réseau social ou transfert in-app directement on-chain. Si chaque utilisateur devait toucher la couche de base pour chaque paiement, les frais et les délais de confirmation rendraient rapidement l'expérience inutilisable.
C'est pourquoi la scalabilité de Bitcoin n'est pas une fonctionnalité unique, c'est une stack. La couche de base fournit le règlement final ; les couches supérieures expérimentent différentes manières de rendre les paiements fréquents moins chers et plus simples.
Lightning fonctionne, mais reste difficile à transformer en produit self-custodial
Le réseau Lightning reste le plus important réseau de paiement construit sur Bitcoin. Il est rapide, largement intégré et de plus en plus utilisé comme rail de paiement commun entre différentes applications Bitcoin.
La difficulté n'est pas que Lightning ne fonctionne pas, la difficulté est de le rendre invisible.
Un wallet Lightning entièrement self-custodial doit gérer les canaux, la liquidité, le routage, les sauvegardes et la surveillance en ligne. Les wallets modernes ont fait d'énormes progrès, notamment grâce aux Lightning Service Providers (LSP), mais l'expérience utilisateur dépend toujours d'une infrastructure que quelqu'un doit opérer.
Pour un développeur qui construit une application mobile, une plateforme sociale, un wallet d'exchange ou un produit de paiement, cela crée un dilemme. La custody donne la meilleure UX, tandis que la self-custody donne la meilleure souveraineté. Lightning donne des paiements rapides, mais ne donne pas automatiquement une expérience produit simple.
Les wallets custodial ont résolu l'UX, mais ont créé un problème réglementaire
Les wallets Lightning custodial ont montré ce que les utilisateurs veulent réellement : des paiements instantanés, des soldes simples, une réception facile et aucune gestion de canaux. Wallet of Satoshi est devenu populaire en grande partie parce qu'il a donné à Lightning l'apparence d'une application de paiement normale.
Mais la custody change la nature du business. Si un wallet détient les fonds des utilisateurs, il peut faire face à des règles de transmission d'argent, à des obligations de conformité, à des restrictions géographiques, à des contrôles de retrait et à une responsabilité directe sur les soldes des utilisateurs. Si les régulateurs exercent une pression, le service peut être forcé de quitter certains marchés, d'imposer des limites ou de modifier son modèle.
Spark donne aux wallets un autre chemin. Un service peut offrir une expérience similaire, un solde simple, des paiements instantanés, une compatibilité Lightning, tout en structurant le système de manière à ce que les utilisateurs détiennent des clés et que le service ne se contente pas de maintenir un ledger custodial interne.
Cela ne rend pas la sécurité de l'utilisateur équivalente à Bitcoin L1, mais cela change la posture produit et réglementaire. Pour les entreprises qui opèrent des wallets et des exchanges, c'est peut-être l'une des fonctionnalités les plus importantes de Spark.
Comment fonctionne Spark
Statechains et signature partagée
Pour comprendre Spark, il faut commencer par le modèle UTXO de Bitcoin.
Bitcoin n'utilise pas des comptes au sens bancaire du terme, le solde d'un wallet est composé d'unspent transaction outputs, ou UTXO. Lorsque vous dépensez des bitcoins, vous consommez un ou plusieurs UTXO et en créez de nouveaux.
Une statechain modifie la manière dont la propriété se déplace, au lieu de créer une nouvelle transaction on-chain à chaque paiement, le système transfère off-chain le contrôle d'une créance liée à Bitcoin. Les coins restent ancrés à Bitcoin, mais le droit de les dépenser change de mains à travers des mises à jour signées.
Dans Spark, l'utilisateur détient une partie du contrôle de signature, tandis que les opérateurs Spark participent collectivement à l'autre côté. Le système peut être compris comme un modèle de signature partagée : les utilisateurs et les opérateurs coopèrent pour mettre à jour qui détient la créance valide la plus récente. Spark utilise une signature distribuée afin que le côté opérateur ne soit pas censé être contrôlé par une seule clé, donc par une seule personne ou entreprise.
C'est ici que FROST entre dans le design, il s'agit d'un schéma de signature à seuil : il permet à plusieurs opérateurs de coopérer pour produire des signatures sans qu'un seul opérateur ne détienne l'ensemble de la clé opérateur. Pour un lecteur non technique, le point important n'est pas le détail cryptographique, mais le rôle que cela joue : Spark essaie d'éviter un custodian unique en divisant le côté opérateur du processus de signature.
Lors d'un transfert, le destinataire doit recevoir un état valide plus récent et un chemin de sortie, et l'ancien propriétaire ne devrait plus pouvoir récupérer les mêmes fonds. Mais cela repose sur une hypothèse cruciale : l'ancien matériel de clé doit être supprimé ou rendu inutilisable par l'ensemble des opérateurs.
Le problème est que, de la même manière qu'il est impossible de prouver que Dieu n'existe pas, nous ne pouvons pas prouver que cette ancienne clé a réellement été supprimée. Si une information a existé dans le passé, nous ne pouvons pas être certains qu'elle n'a pas été copiée ou sauvegardée.
Ainsi, pour utiliser Spark, vous devez faire confiance au fait que l'opérateur a effectivement supprimé son accès à vos fonds, de la même manière que vous feriez confiance à un custodian pour ne pas vous rug-pull.
Feuilles et soldes
Spark introduit aussi une structure en arbre, au lieu de traiter un dépôt comme une seule créance indivisible, les soldes peuvent être représentés à travers des branches et des feuilles.
Les feuilles sont les parties terminales de l'arbre, ce sont les morceaux détenus par les utilisateurs. Les branches sont des transactions intermédiaires qui aident à organiser ces feuilles. Cette structure permet de diviser, recombiner et transférer de la valeur avec moins d'interactions on-chain, ce qui rend ces opérations moins coûteuses.
Pour l'utilisateur, cela peut ressembler à un solde de wallet normal, mais en arrière-plan, le wallet doit suivre un état off-chain plus complexe. Il doit savoir quelles feuilles il contrôle, comment elles sont liées aux transactions parentes et comment sortir si la coopération échoue.
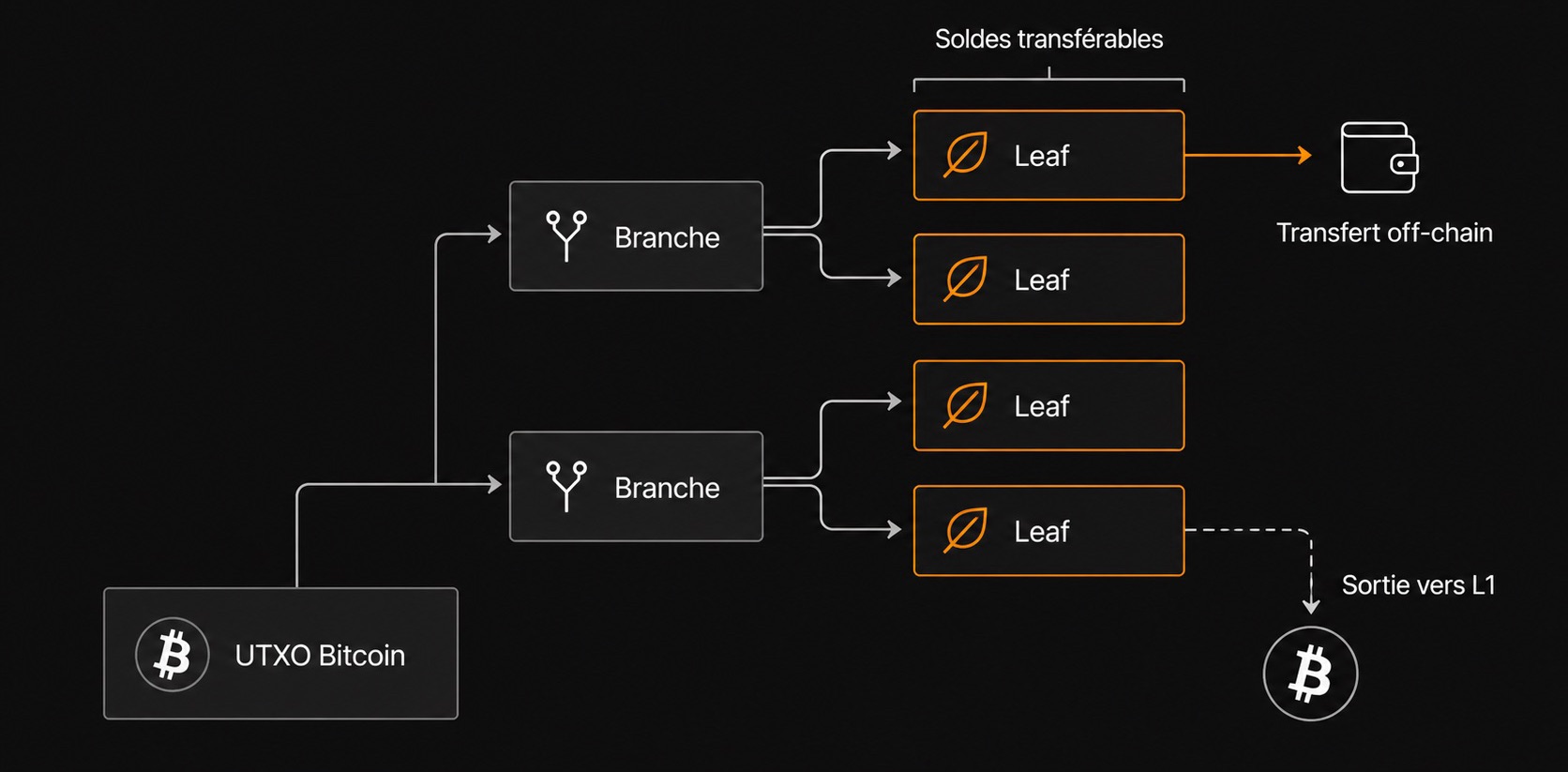
Cette structure est importante parce que l'expérience utilisateur peut être simple alors que le modèle de récupération reste technique. Un wallet Spark peut donner l'impression d'un solde dans une application de néobanque, mais la garantie dépend de la capacité du wallet à conserver et utiliser les bonnes données de sortie.
Opérateurs et fournisseurs de service
Les opérateurs Spark ne sont pas des acteurs secondaires optionnels. Ils font partie du fonctionnement normal du protocole.
La Spark Entity coordonne les signatures et les transitions d'état, les Spark Operators individuels participent à cette entité, et les Spark Service Providers aident les utilisateurs à passer entre Spark, Bitcoin L1 et Lightning. Ils peuvent faciliter les dépôts, les retraits, les swaps et les paiements Lightning.
Quand tout fonctionne, l'utilisateur les voit à peine, l'application reçoit, l'application envoie, les invoices Lightning sont payées et le solde se met à jour.
Quand quelque chose casse, le rôle de l'opérateur devient central. Les opérateurs sont-ils en ligne ? Sont-ils indépendants ? Peuvent-ils censurer ? Quelles métadonnées voient-ils ? Les utilisateurs peuvent-ils sortir à faible coût ? Un wallet peut-il récupérer sans la coopération du fournisseur ? L'ensemble d'opérateurs est-il suffisamment grand pour que l'hypothèse “au moins un opérateur honnête” ait un sens ?
Selon la propre FAQ de Spark, le réseau a été lancé avec un petit ensemble d'opérateurs, incluant initialement Lightspark et Flashnet, avec l'intention affichée d'ajouter davantage d'opérateurs au fil du temps. C'est compréhensible pour un système en bêta, mais cela compte aussi pour le modèle de confiance. Une hypothèse 1-of-N n'est aussi forte que l'indépendance pratique, les incitations et la distribution réelle de N.
Comment Spark interagit avec Lightning
Spark ne remplace pas Lightning, il l'utilise comme rail de paiement externe qui connecte les wallets Spark au reste de l'écosystème Bitcoin, et l'utilisateur ne gère pas de canal Lightning à l'intérieur de Spark. À la place, les Spark Service Providers, ou les fournisseurs Lightning connectés à Spark, gèrent la partie Lightning tandis que le solde de l'utilisateur est mis à jour à travers les transferts de type statechain propres à Spark.
Lorsqu'un utilisateur Spark reçoit via Lightning, le payeur paie toujours une invoice Lightning, mais le receveur n'a pas besoin de faire tourner un node, d'ouvrir un canal, de gérer la liquidité entrante ou de rester en ligne comme dans un wallet Lightning self-custodial traditionnel. Le paiement est transféré dans Spark, et le receveur se retrouve avec des fonds Spark.
Lorsqu'un utilisateur Spark paie une invoice Lightning, le processus fonctionne en sens inverse : des feuilles Spark sont transférées conditionnellement, le fournisseur Lightning paie l'invoice, et Spark finalise lorsque la preuve de paiement est disponible.
Spark est-il self-custodial ?
C'est la question la plus importante de l'article.
La documentation de Spark et les annonces de ses partenaires décrivent le système comme self-custodial. Dans un sens limité, cela se comprend. Les utilisateurs ont des clés. Les opérateurs ne sont pas censés pouvoir déplacer les fonds seuls. Spark inclut des transactions de sortie unilatérales censées permettre aux utilisateurs de retirer vers Bitcoin L1 sans coopération des opérateurs.
Mais si “self-custody” signifie la même garantie que la détention d'un UTXO Bitcoin normal avec votre propre clé privée, Spark ne respecte pas ce standard.
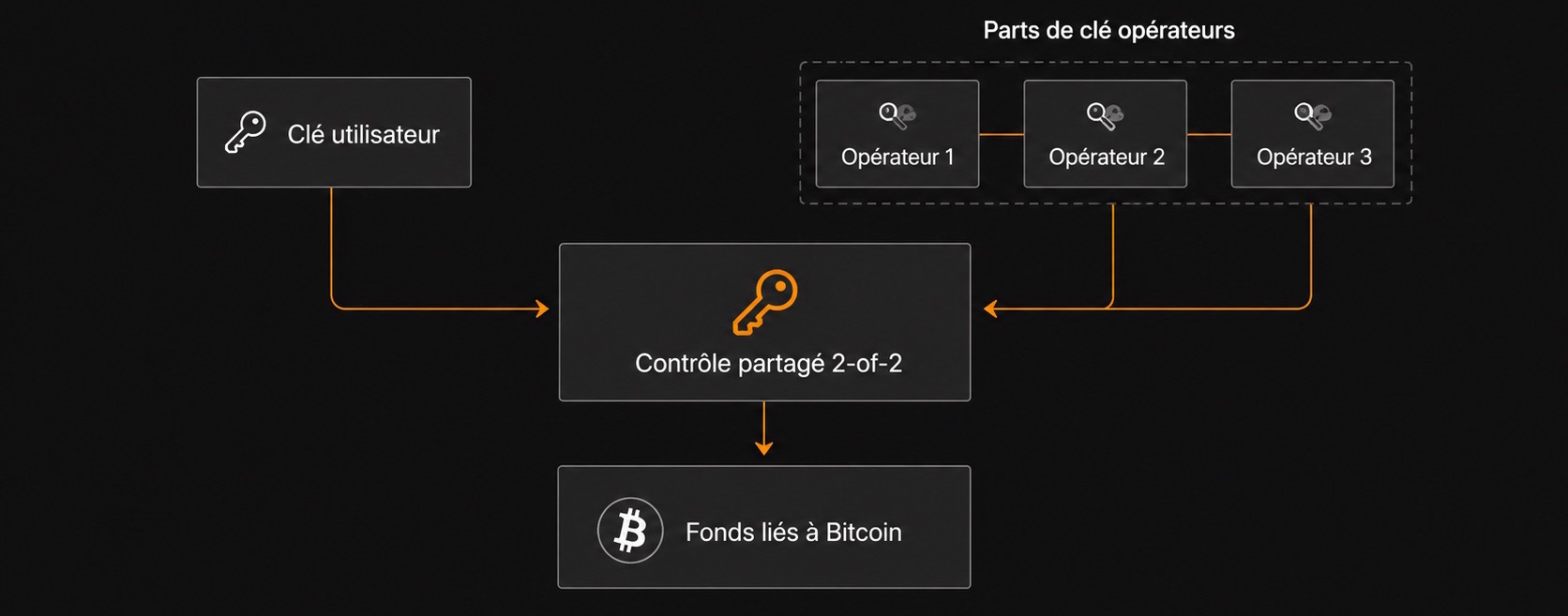
L'utilisateur a une clé, mais pas les garanties de Bitcoin L1
Avec un UTXO Bitcoin normal, le modèle est direct, si vous contrôlez la clé privée, vous pouvez signer une transaction, la diffuser au réseau, vous dépendez encore des frais et de l'inclusion dans un bloc, mais vous ne dépendez pas d'un opérateur qui aurait oublié un ancien état.
Spark est différent. L'utilisateur détient une clé et devrait avoir un chemin de sortie, mais le fonctionnement normal du système dépend de la signature partagée, d'un état off-chain, des opérateurs et de mises à jour correctes des clés. Un solde Spark n'est pas le même objet qu'un simple UTXO on-chain.
Cela ne fait pas de Spark un wallet custodial au sens classique. Un wallet Spark qui fonctionne correctement n'est pas simplement un solde de compte sur le serveur d'une entreprise, mais il ne devrait pas non plus être décrit comme équivalent à de la self-custody Bitcoin directe.
Spark offre une expérience utilisateur qui ressemble à de la self-custody, mais pas la même garantie de self-custody que la détention directe de bitcoins on-chain.
Le problème critique : la suppression des clés ne peut pas être vérifiée
La faiblesse critique de Spark n’est pas que la Spark Entity puisse simplement déplacer les fonds seule dans l’état actuel. En théorie, elle ne le peut pas.
Spark repose sur une forme de garde collaborative fondée sur une structure en deux-sur-deux : une partie est détenue par l’utilisateur actuel, tandis que l’autre est détenue par la Spark Entity. Le pouvoir de signature de la Spark Entity est lui-même distribué entre plusieurs opérateurs grâce aux signatures à seuil FROST. Pour produire une dépense valide depuis l’état actuel, le propriétaire actuel et la Spark Entity doivent donc tous les deux participer.
Le risque principal vient du mécanisme de transfert utilisé par les statechains.
Quand Alice transfère des fonds à Bob, les bitcoins ne bougent pas on-chain. Spark transfère plutôt la capacité off-chain de dépenser l’UTXO lié à ces bitcoins. Bob reçoit un nouvel état et une nouvelle capacité cryptographique, tandis que la Spark Entity participe à un processus de rotation des clés et doit supprimer l’ancien matériel cryptographique opérateur lié à Alice.
Cette suppression est l’étape critique.
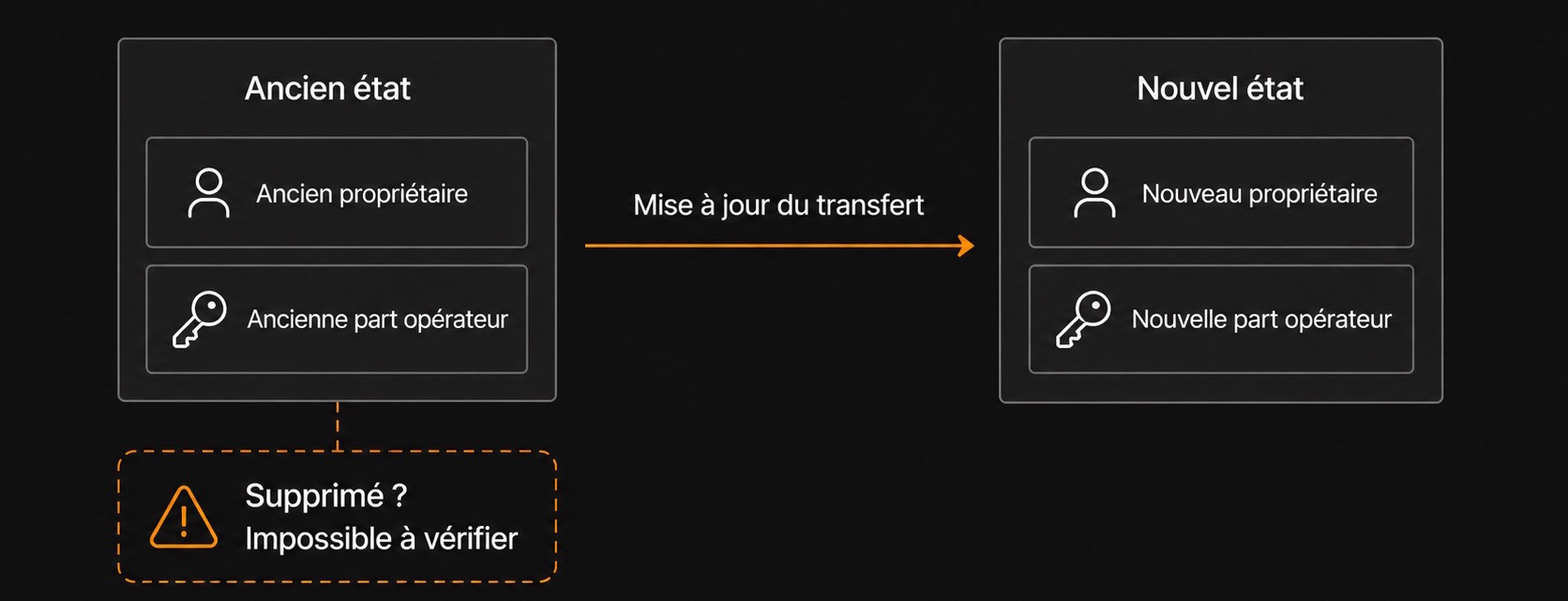
Si un seuil suffisant d’opérateurs conserve l’ancienne part opérateur au lieu de la supprimer, ils peuvent potentiellement colluder avec Alice, l’ancienne propriétaire, pour reconstruire l’ancien état en 2-sur-2 : l’ancienne clé utilisateur d’Alice d’un côté, et l’ancienne part de la Spark Entity conservée par les opérateurs de l’autre.
💡 Que se passera-t-il si Bitcoin échoue à devenir une monnaie ?
Dans ce scénario, la Spark Entity ne vole pas seule. Elle a besoin de l’ancien propriétaire. Mais si l’ancien propriétaire et un seuil suffisant d’opérateurs colludent, ils peuvent tenter de faire revivre un ancien état et de double-spend contre le nouvel état de Bob.
C’est la distinction exacte en matière de garde. Spark n’est pas custodial au sens strict, car la Spark Entity ne peut pas signer seule dans l’état actuel. Mais ce n’est pas non plus de la self-custody forte au sens de Bitcoin L1, car la finalité d’un transfert dépend de la suppression effective d’anciens secrets opérateurs, et l’utilisateur ne peut pas vérifier cryptographiquement que cette suppression a bien eu lieu.
C’est pour cette raison que le modèle d’opérateurs 1-of-N de Spark est important. Si au moins un opérateur dont la coopération serait nécessaire pour reconstruire l’ancienne part de la Spark Entity se comporte honnêtement et supprime son ancien secret, l’ancien état devient inutilisable. Mais cette garantie repose toujours sur une hypothèse de comportement des opérateurs, et non sur une preuve que l’utilisateur peut vérifier indépendamment.
L’utilisateur ne fait peut-être plus confiance à un custodian au sens classique, mais il fait encore confiance à l’ensemble des opérateurs pour oublier ce que le protocole exige qu’ils oublient.
C’est la différence entre une self-custody forte et une self-custody comme architecture produit.
Pourquoi les wallets et les exchanges peuvent adopter Spark
Cette ambiguïté n'est pas un détail. C'est peut-être l'une des raisons pour lesquelles Spark est attractif.
Les wallets et les plateformes veulent l'expérience utilisateur de la custody sans le risque de la custody. Ils veulent que les utilisateurs ouvrent une application, reçoivent instantanément, paient des invoices Lightning, envoient de petits montants et ne pensent jamais aux canaux ou à la liquidité. Mais ils veulent aussi éviter d'être l'entité qui détient simplement les coins de tout le monde.
Spark offre une possible porte de sortie, un wallet peut dire que l'utilisateur a des clés, le service peut intégrer des paiements Lightning-like, et l'application peut conserver l'expérience familière d'un solde. Le rôle de l'intermédiaire change : il passe de pur custodian à fournisseur d'infrastructure, opérateur, fournisseur de service ou intégrateur de SDK.
Wallet of Satoshi est l'exemple le plus clair, Spark a annoncé en juillet 2025 que le portefeuille était live sur Spark avec une expérience Lightning self-custodial, et a explicitement indiqué que cette intégration permettait à la plateforme de servir à nouveau le marché américain. Cake Wallet a ensuite ajouté le support Lightning via le Breez SDK construit sur l'infrastructure Spark, même chose pour le wallet Primal.
Ces exemples ne doivent pas être lus comme une preuve que Spark donne aux utilisateurs la même garantie que Bitcoin L1. Ils montrent autre chose : Spark résout un problème produit pour des wallets qui veulent une UX custodial-like sans architecture directement custodial.
Spark peut être attractif parce qu'il donne aux intermédiaires un moyen de conserver l'expérience utilisateur de la custody tout en renvoyant une partie de la charge de custody vers l'utilisateur.
Pour les entreprises, ce n'est pas seulement un argument produit, c'est surtout un argument réglementaire. Spark donne aux wallets et aux exchanges un moyen d'affirmer qu'ils ne détiennent plus simplement les soldes clients comme un custodian classique, mais qu'ils fournissent une infrastructure autour d'un solde contrôlé par l'utilisateur avec un chemin de sortie. Cela ne règle pas la question juridique, et la réponse dépendra de la juridiction et de l'implémentation, mais cela peut réduire l'exposition liée à la custody qui a poussé certains wallets Lightning hors de certains marchés.
C'est utile. C'est aussi exactement pour cela que les utilisateurs doivent être prudents avec le mot “self-custody”.
Spark vs Ark : 2 façons d'éviter la complexité de Lightning
Le protocole Spark et le protocole Ark sont souvent évoqués ensemble parce qu'ils répondent à un problème similaire. Ce sont 2 protocoles de scaling Bitcoin qui peuvent rendre les paiements plus simples sans demander à chaque utilisateur de gérer directement des canaux Lightning. Les 2 peuvent se connecter à Lightning. Les 2 déplacent la complexité loin de l'utilisateur final.
Mais ils ne déplacent pas cette complexité au même endroit.
Ark donne aux utilisateurs des virtual UTXOs, ou VTXO, coordonnés par un opérateur et rafraîchis à travers des rounds. Spark utilise des transferts de propriété de type statechain, de la signature partagée, des feuilles et des mises à jour de clés opérateur. Dans les 2 cas, Bitcoin reste la couche de règlement final, tandis que Lightning reste le rail de paiement utilisé pour atteindre le reste de l'écosystème.
Ark utilise des VTXO et des rounds ; Spark utilise des statechains et des mises à jour de clés opérateur
Les compromis d'Ark sont plus faciles à décrire dans des termes temporels : entre les rounds, l'utilisateur a des garanties plus faibles, mais après le settlement, les droits de sortie deviennent plus forts. L'expiration des VTXO, la participation aux rounds et la liquidité de l'opérateur sont au centre du modèle.
Le compromis de Spark est davantage centré sur l'intégrité de l'état et le comportement des opérateurs. L'expérience utilisateur peut être plus fluide, mais le modèle de sécurité dépend fortement de la suppression des anciennes clés et du comportement requis de l'ensemble des opérateurs.

À quoi peut servir Spark ?
Le cas d'usage le plus évident est celui des wallets mobiles. Spark peut donner aux développeurs de wallets un moyen d'offrir des paiements bitcoin rapides, une interopérabilité Lightning et une réception simple, sans forcer les utilisateurs à ouvrir des canaux ou à gérer de la liquidité.
Cela le rend pertinent pour plusieurs catégories :
- wallets Bitcoin grand public ;
- applications sociales avec micropaiements ou tips de créateurs ;
- exchanges ou applications fintech qui veulent des dépôts, retraits ou paiements Bitcoin plus rapides ;
- outils de paiement marchand ;
- applications qui nécessitent de petits paiements fréquents ;
- wallets qui veulent proposer des Lightning addresses sans devenir des custodians purs.
Le positionnement du Spark SDK de Breez est particulièrement important ici, il présente Spark comme un moyen pour les développeurs d'ajouter du bitcoin instantané et non-custodial dans des applications, et liste de nombreuses intégrations ou partenaires. Cela suggère que Spark pourrait se diffuser moins comme un protocole consciemment choisi par les utilisateurs que comme une infrastructure cachée à l'intérieur des applications.
C'est ainsi que la plupart des technologies de paiement atteignent les utilisateurs mainstream, ils ne choisissent pas le protocole, ils choisissent l'application.
Stablecoins et tokens : utiles, mais pas la garantie centrale de Bitcoin
Spark supporte aussi des cas d'usage liés aux tokens et aux stablecoins. L'annonce initiale de Lightspark mettait en avant l'émission de stablecoins comme une partie de la direction produit, et la documentation de Spark décrit le support des tokens.
Cela doit être traité séparément des paiements en bitcoin.
Un solde bitcoin sur Spark a déjà un modèle de sécurité différent d'un UTXO Bitcoin direct. Un stablecoin sur Spark ajoute une autre couche de confiance : risque d'émetteur, règles de gel, risque de rachat, contraintes réglementaires et exigences de conformité. Même si Spark offre des transferts rapides, il ne peut pas transformer un actif émis de manière centralisée en bitcoin.
Les stablecoins peuvent être utiles pour des applications de paiement, mais ils ne doivent pas être mélangés rhétoriquement avec les garanties de self-custody de Bitcoin.
Les limites et les risques de Spark
Une fausse impression de self-custody
Le plus grand risque de Spark est peut-être sémantique. Si les utilisateurs entendent “self-custodial” et comprennent “identique à la détention de bitcoins on-chain”, ils comprendront mal le produit.
Spark n'est pas un compte d'exchange custodial. Mais il n'est pas non plus identique à un wallet Bitcoin normal. C'est un modèle assisté, dépendant d'opérateurs, avec un chemin de sortie.
Cette distinction compte surtout lorsque quelque chose se passe mal.
La suppression des clés ne peut pas être prouvée
L'opérateur doit oublier l'ancien matériel de clé. Le protocole dépend de cela. Mais l'utilisateur ne peut pas vérifier directement la suppression.
Cela rend Spark différent des modèles où un comportement incorrect est puni ou entièrement empêché par des mécanismes on-chain. La sécurité de Spark est trust-minimized, pas trustless. Elle dépend du fait qu'au moins un opérateur se comporte correctement dans le processus pertinent de suppression des clés.
Dépendance aux opérateurs
Si tous les opérateurs sont hors ligne, la FAQ de Spark indique que les utilisateurs ne peuvent pas effectuer de nouveaux transferts Spark jusqu'au retour des opérateurs, même s'ils devraient toujours pouvoir sortir vers Bitcoin L1 avec des transactions pré-signées.
C'est un problème de liveness plutôt qu'un vol immédiat, mais cela reste important. Les systèmes de paiement ont besoin d'uptime. Un wallet qui ne fonctionne que lorsque son infrastructure opérateur fonctionne reste dépendant de cette infrastructure.
Risques de privacy
Les paiements Spark ne sont pas automatiquement privés simplement parce qu'ils n'apparaissent pas comme des paiements on-chain ordinaires.
Les opérateurs peuvent voir des informations de transaction. Les fournisseurs de service peuvent voir les flux entre Spark et Lightning. Certaines implémentations peuvent fuiter des métadonnées via les adresses, les invoices ou des explorers. L'annonce Spark de Cake met en avant des paramètres de privacy par défaut comme le fait de ne pas diffuser les adresses Spark dans les invoices Lightning et de ne pas publier les transactions sur un registre public, ce qui montre implicitement qu'il s'agit de choix d'implémentation, pas de propriétés automatiques de chaque wallet Spark.
La privacy dépend donc du wallet, des politiques des opérateurs et des choix de publication des données.
Complexité de sortie
Le chemin de sortie est essentiel à la revendication de self-custody de Spark, mais une sortie théorique n'est pas la même chose qu'une sortie simple.
Les utilisateurs ont besoin des bonnes données, le wallet doit les conserver, et les frais on-chain doivent rester abordables. En fonctionnement normal, un wallet Spark peut paraître instantané et peu coûteux. En situation de stress, sortir vers L1 peut devenir plus lent, plus cher et plus technique.
Cela ne rend pas Spark inutile. Cela signifie que le chemin de sortie doit être testé et expliqué, pas seulement mentionné.
Ambiguïté réglementaire
Si Spark devient attractif parce qu'il réduit l'apparence ou la structure de la custody, les régulateurs peuvent finir par examiner la substance réelle du contrôle.
L'utilisateur contrôle-t-il réellement les fonds ? Le service peut-il geler, censurer ou empêcher l'usage normal ? À quel point la sortie unilatérale est-elle pratique ? Les opérateurs sont-ils indépendants ? Qui contrôle l'interface utilisateur, le processus de récupération et le flux de transactions ?
Ces questions comptent parce que Spark peut se situer dans la même zone grise techniquement et juridiquement : ni pur custodian, ni pure self-custody.
Maturité
Spark est encore jeune. Sa propre FAQ décrit l'environnement comme une bêta, avertit que des limites peuvent s'appliquer et indique que l'ensemble initial d'opérateurs est petit. Ce n'est pas inhabituel pour un nouveau protocole, mais cela doit tempérer les affirmations sur une trustlessness prête pour la production.
Bitcoin L1 a été testé pendant plus d'une décennie. Lightning a plusieurs années d'usage réel. Spark est plus récent et doit être traité en conséquence.
Spark est-il un Layer 2 Bitcoin ?
Spark peut raisonnablement être décrit comme un Layer 2 Bitcoin, mais seulement si le terme est utilisé avec prudence.
Ce n'est pas une blockchain séparée comme une sidechain, ce n'est pas un rollup, il n'introduit pas de machine virtuelle ou d'environnement de smart contracts, il ne remplace pas Lightning.
Spark est une couche de coordination off-chain construite sur Bitcoin. Les utilisateurs déplacent de la valeur liée à Bitcoin à l'intérieur de Spark via de la signature partagée et des transferts de type statechain, tandis que Bitcoin L1 reste la couche finale de sortie et de règlement.
Le label “Layer 2” est donc acceptable, mais le mécanisme compte davantage que la catégorie. Le modèle de confiance de Spark n'est pas celui de Lightning, ni celui de Liquid, ni celui d'Ark. C'est son propre compromis.
La place de Spark dans la stack de scaling de Bitcoin
La scalabilité de Bitcoin devient modulaire.
Bitcoin L1 fournit les règles monétaires, la résistance à la censure et le règlement final. Lightning fournit des paiements routés rapides. Liquid propose un modèle de sidechain fédérée avec un settlement plus rapide et l'émission d'actifs. Ark explore les VTXO, les rounds et le settlement coordonné par un opérateur. Cashu offre de l'e-cash avec une excellente UX mais une custody fondée sur des mints. Spark ajoute des statechains, de la signature partagée et une couche de paiement compatible avec les wallets qui peut se connecter à Lightning.
Aucune couche ne résout tous les problèmes. Chacune choisit un point différent dans l'espace des compromis : UX, custody, privacy, liquidité, frais, régulation et récupérabilité.
La place de Spark dans cette stack est claire, ce n'est pas la manière la plus trustless de détenir des bitcoins, ce n'est pas le modèle le plus simple à expliquer, mais cela pourrait devenir l'un des moyens les plus faciles pour des applications d'offrir des paiements Bitcoin sans devenir pleinement custodial.
C'est pourquoi Spark compte, et pourquoi il mérite d'être examiné de près.
Conclusion : pourquoi Spark compte
Spark compte parce qu'il répond à un véritable goulot d'étranglement : Lightning self-custodial est trop complexe pour beaucoup de wallets, d'applications et d'utilisateurs. Si les paiements Bitcoin doivent apparaître dans des applications sociales, des wallets mobiles, des exchanges, des outils marchands et des produits fintech grand public, les développeurs ont besoin d'une infrastructure qui masque les canaux, la liquidité et le routage.
Spark offre une voie. Il permet aux wallets de fournir une expérience de paiement familière tout en réduisant l'exposition à la custody directe. Cela peut expliquer pourquoi des projets comme Wallet of Satoshi, Cake Wallet et Primal se sont orientés vers une infrastructure ou des SDK fondés sur Spark.
Mais l'utilisateur ne doit pas confondre commodité réglementaire et self-custody forte. Spark déplace le risque de custody dans une zone plus ambiguë : l'utilisateur a une clé, mais l'opérateur compte toujours ; le wallet semble simple, mais les garanties sont plus faibles que la détention directe de bitcoins ; le système peut être non-custodial dans sa forme, mais pas totalement trustless dans sa substance.
Spark est important non pas parce qu'il supprime la confiance des paiements Bitcoin, mais parce qu'il montre combien de confiance les utilisateurs peuvent accepter lorsque l'alternative est un wallet qui fonctionne simplement.
FAQ
Qu'est-ce que Spark dans Bitcoin ?
Spark est un Layer 2 Bitcoin construit sur des statechains et de la signature partagée. Il permet aux utilisateurs d'effectuer des transferts off-chain rapides de valeur liée à Bitcoin, tout en conservant un chemin de sortie vers Bitcoin L1.
Spark est-il self-custodial ?
Spark est self-custodial dans un sens plus faible et assisté : les utilisateurs détiennent des clés et devraient disposer d'un chemin de sortie unilatéral. Mais ce n'est pas équivalent à la détention directe d'un UTXO Bitcoin normal on-chain, car l'usage ordinaire dépend des opérateurs et de la suppression de l'ancien matériel de clé.
Pourquoi les wallets adoptent-ils Spark ?
Les wallets peuvent utiliser Spark pour offrir une expérience proche de Lightning custodial sans détenir directement les fonds des utilisateurs de la même manière. Cela peut réduire la complexité technique et potentiellement réduire l'exposition réglementaire liée à la custody, même si le traitement juridique exact dépend de la juridiction et de l'implémentation.
Spark supprime-t-il le risque de custody ?
Non. Spark modifie le modèle de custody. Il réduit le risque custodial direct par rapport à un wallet qui détient simplement les soldes utilisateurs, mais il introduit des hypothèses de confiance envers les opérateurs, une complexité de sortie et un risque de gestion d'état.
Que se passe-t-il si un opérateur Spark conserve d'anciennes clés ?
La sécurité de Spark dépend du fait que les opérateurs suppriment ou oublient l'ancien matériel de clé après les transferts. Si tous les opérateurs pertinents conservaient d'anciens secrets et colludaient avec un ancien propriétaire, la protection du système contre le double-spend serait affaiblie. C'est pourquoi l'hypothèse 1-of-N de Spark est importante.
Les utilisateurs Spark peuvent-ils sortir vers Bitcoin L1 ?
Oui, Spark est conçu autour de transactions de sortie pré-signées qui permettent aux utilisateurs de retirer des fonds vers Bitcoin L1 sans coopération des opérateurs. La sécurité pratique de cette sortie dépend de l'implémentation du wallet, de la disponibilité des données et des frais on-chain.
Quelle est la différence entre Spark et Ark ?
Ark repose sur des VTXO, des rounds, des refreshs et un settlement coordonné par un opérateur. Spark repose sur des transferts de type statechain, de la signature partagée, des feuilles et des mises à jour de clés opérateur. Les 2 cherchent à réduire la complexité de Lightning, mais Spark est plus directement adapté à une UX de wallet custodial-like, tandis qu'Ark rend les cycles de settlement plus explicites.
Spark est-il plus sûr qu'Ark ?
Pas dans un sens simple oui ou non. Ark et Spark font des compromis différents. Ark présente des risques autour des opérateurs, de la liquidité, de l'expiry et des rounds. Spark présente des risques autour des opérateurs, de la suppression des clés, de la privacy et des attentes trompeuses autour de la self-custody.
Spark peut-il supporter des stablecoins ?
Oui, Spark supporte des cas d'usage liés aux tokens et aux stablecoins. Mais les stablecoins introduisent un risque d'émetteur, un risque de gel et un risque réglementaire. Leurs garanties ne doivent pas être confondues avec celles de Bitcoin.
Spark est-il plus sûr qu'un wallet custodial ?
Dans de nombreux cas, Spark devrait offrir un contrôle utilisateur plus fort qu'un wallet purement custodial, parce que les utilisateurs détiennent des clés et devraient avoir un chemin de sortie. Mais ce n'est toujours pas équivalent à de la self-custody on-chain directe.
Source : Spark







